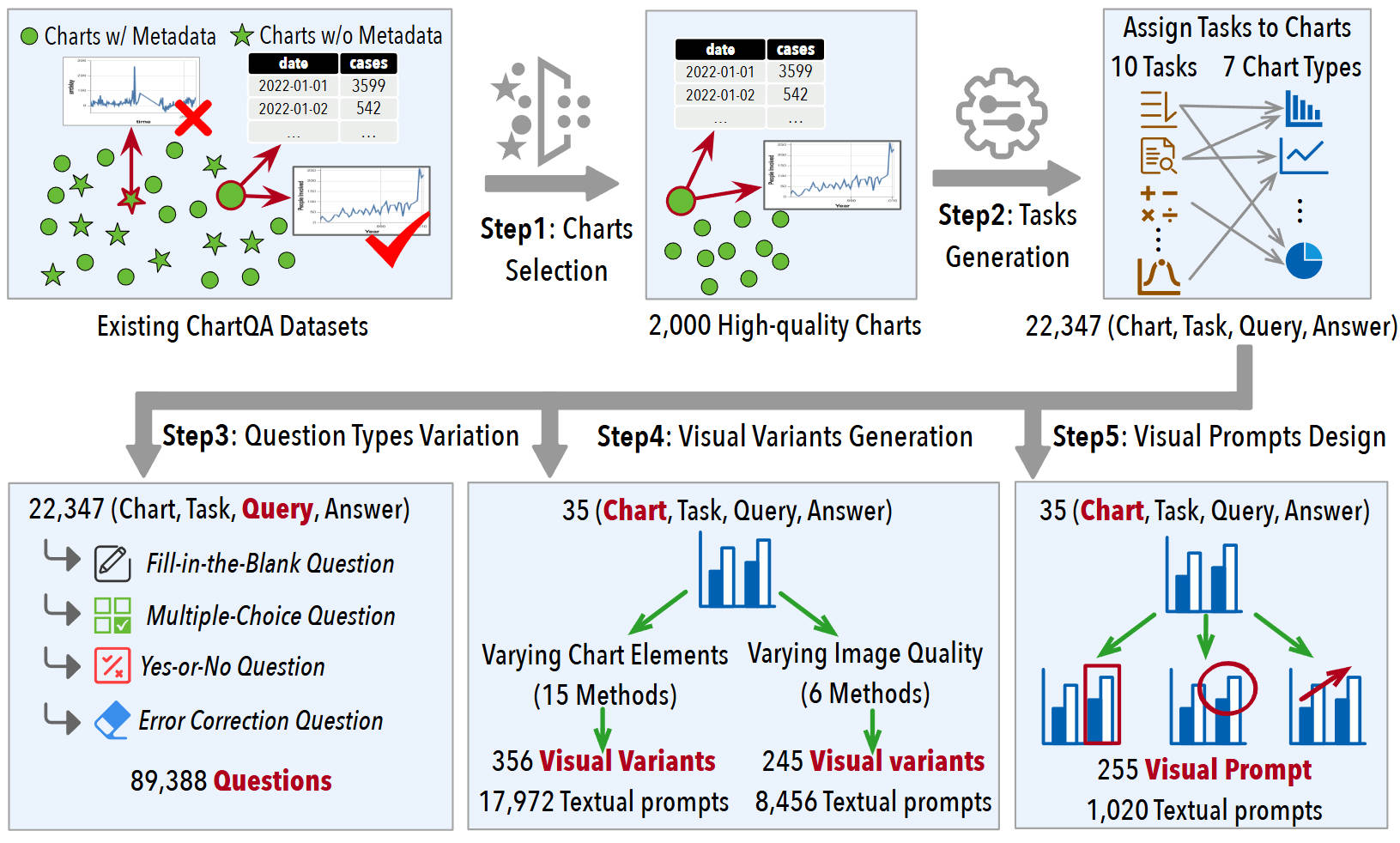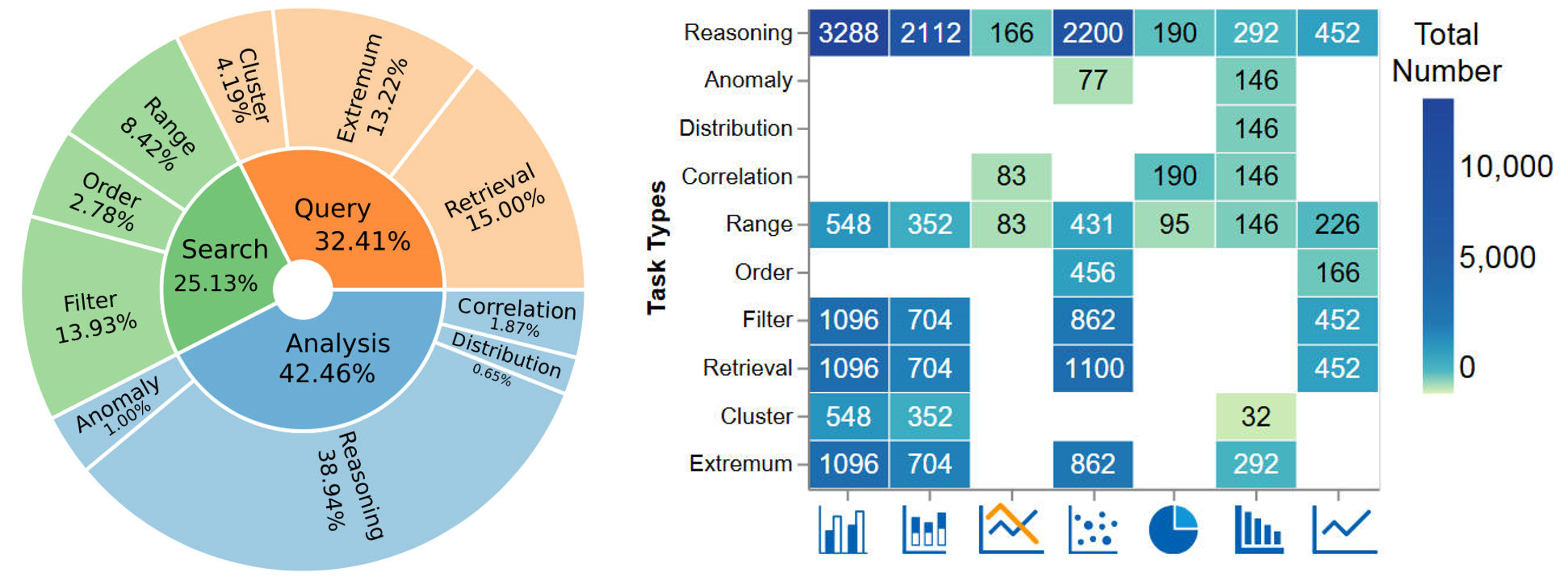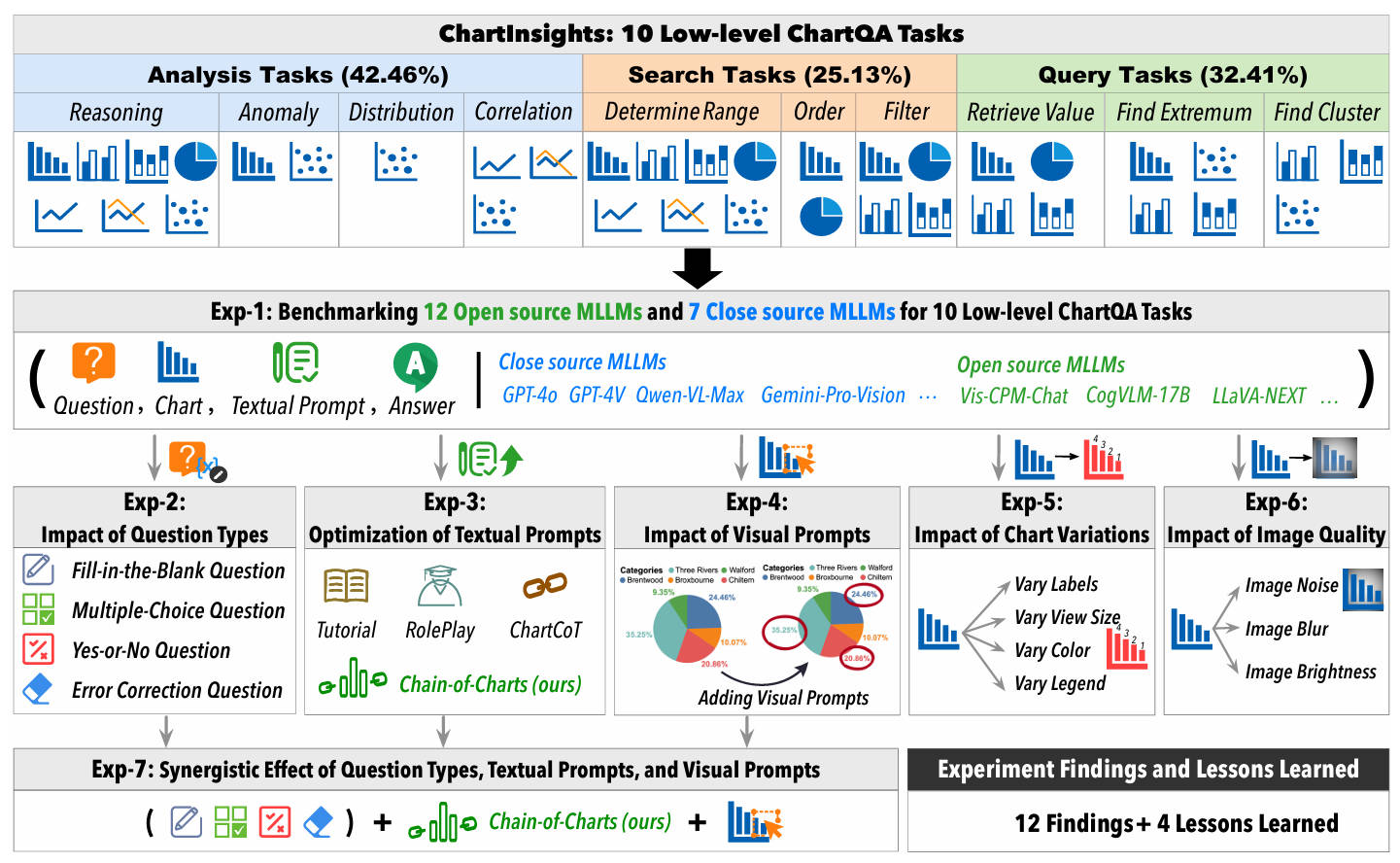
Chart question answering (ChartQA) tasks play a critical role in interpreting and extracting insights from visualization charts. While recent advancements in multimodal large language models (MLLMs) like GPT-4o have shown promise in high-level ChartQA tasks, such as chart captioning, their effectiveness in low-level ChartQA tasks (e.g. identifying correlations) remains underexplored. In this paper, we address this gap by evaluating MLLMs on low-level ChartQA using a newly curated dataset, ChartInsights, which consists of 22,347 (chart, task, query, answer) covering 10 data analysis tasks across 7 chart types.
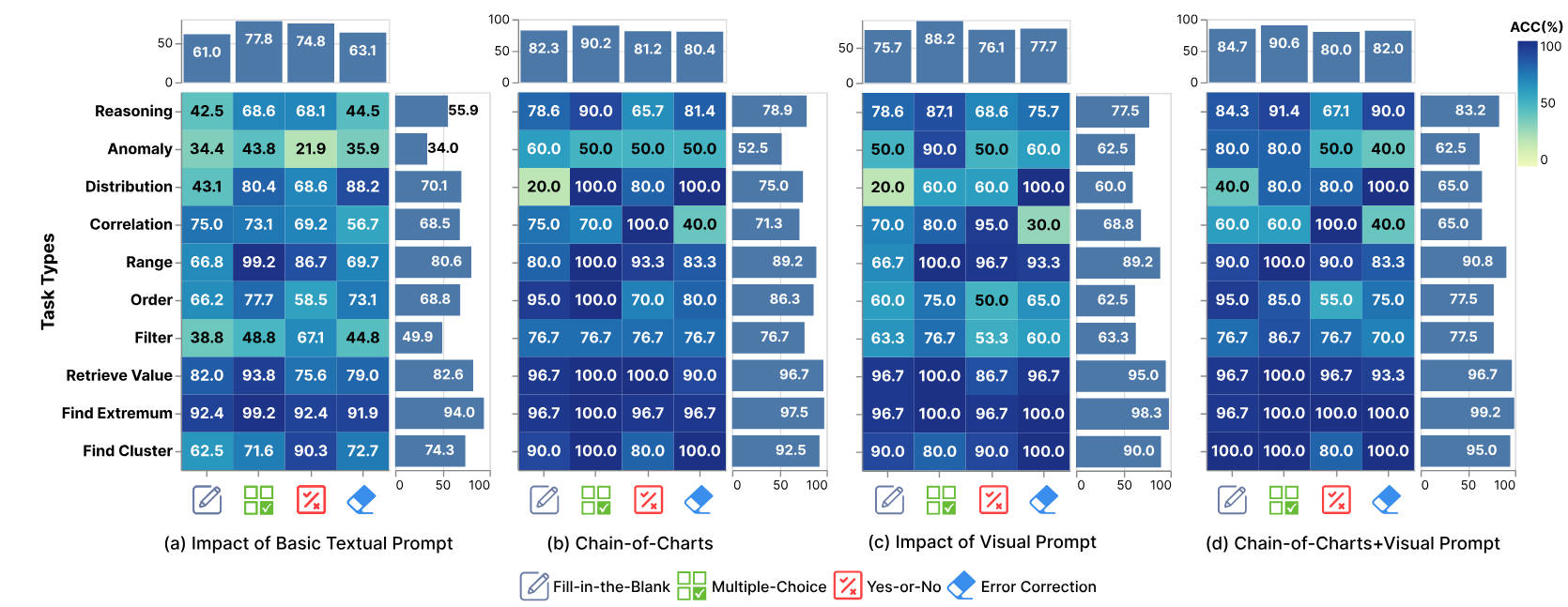
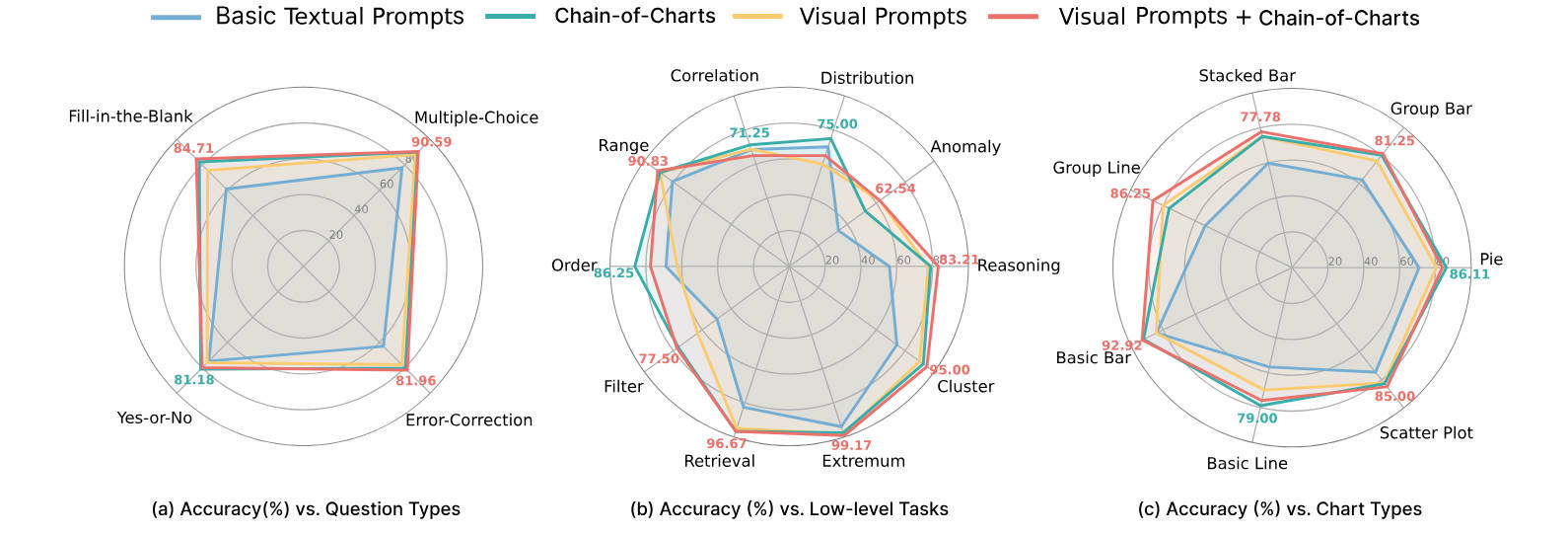
We systematically evaluate 19 advanced MLLMs, including 12 open-source and 7 closed-source models. The average accuracy rate across these models is 39.8%, with GPT-4o achieving the highest accuracy at 69.17%. To further explore the limitations of MLLMs in low-level ChartQA, we conduct experiments that alter visual elements of charts (e.g. changing color schemes, adding image noise) to assess their impact on the task effectiveness. Furthermore, we propose a new textual prompt strategy, Chain-of-Charts, tailored for low-level ChartQA tasks, which boosts performance by 14.41%, achieving an accuracy of 83.58%. Finally, incorporating a visual prompt strategy that directs attention to relevant visual elements further improves accuracy to 84.32%.
Our contributions are summarized as follows: